
pypontem : Hello World!
Our first dive into open-source

Here’s a little tease, but first some background!
Embracing all things data
Pontem Analytics was founded on a simple principle: the best solutions to technical challenges come from combining deep domain expertise with cutting-edge data science. At Pontem, we leverage both traditional engineering knowledge and modern analytics to help clients optimize operations, solve complex problems, and make confident data-driven decisions.
But when we talk about data, we should really clarify that data can come in two high-level forms:
First, there's "wild data", or data from operations and production. This is data that is actually measuring a real system and has either been recorded manually or more likely cataloged in a historian system.
And then there's "simulated data", or data generated by other software-based tools.
At Pontem, we work extensively with both types, but the focus today is on simulated data.

Wrangling data by embracing open-source
Within our tool belt, we often predict complex system dynamics by using industrial software, and along with that we produce gigabytes of simulation data each day. While this data isn’t messy in the same way that wild data can be i.e. it generally has no missing values or random anomalies that can’t be explained, it can still be unruly to extract and organize.
Being the data-focused company that we are, we have embraced this aspect since we started by building processes that help us work efficiently, enable automation, and ultimately allow us to produce insights quickly.
Something we are very mindful of is that much of the technology stack that we use to carry out this data processing is built on a foundation of open-source contributions. Starting first with the language itself, Python in our case, and building beyond that with packages like Numpy, Pandas, and Matplotlib. (As an aside, much of the general population would probably be shocked to know just how much of the things they interact with routinely are also built from on a foundation based on open-source contributions.)
But coming back to our workflow at Pontem, much of what we had built, despite being rather streamlined, was not organized and maintained in the manner it needed to be. In short, what we had were custom scripts scattered throughout the company, but what we needed was a properly maintained package containing all the code in one location.
While much of our staff is aware of numerous 3rd party tools for simulation data extraction such as PyFAs, which offered much of what we were looking for, in the end, the desire to write our own version, custom built for our preferences, while being able to drive future development was too tempting for us…
Introducing pypontem!
Today we’re introducing our very own, in-house built python library for advanced data extraction from simulation based tools - welcome pypontem!
Over the past year, we have been hard at work developing this toolkit internally, collecting and organizing the various scripts we had, and placing them into a single library while building a unified syntax around it.
We have increasingly started using the tool internally, encouraging our own team to break out of Excel silos and build automation and coding into what they do.
But are you really a data science company without embracing and contributing to open-source??
This was a question we started asking ourselves during the development of pypontem only to realize that if we want to move our industry forward, the best thing we can do is not only encourage these approaches internally, but externally as well. And so for that reason, we are also announcing that pypontem has been released as an open-source project and we look forward to building it further with a community of support behind it.

Great, so what does pypontem actually do?
As of today, the pypontem library has the following key features below and is focused initially on OLGA data extraction to start. We anticipate more interfaces coming down the road based on user feedback and community direction:
Multi-variable data extraction: In one-go, specify all the variables you need to extract from tpl and ppl files
Unit conversion: A robust in-built unit conversion functionality which does unit conversions as well as dimensionality checks
Merging of branches: Easily merge together profiles in one-go, without having to do the dirty work yourself in an Excel sheet
Batch parsing: Parse and process an entire batch of simulations with just one function call
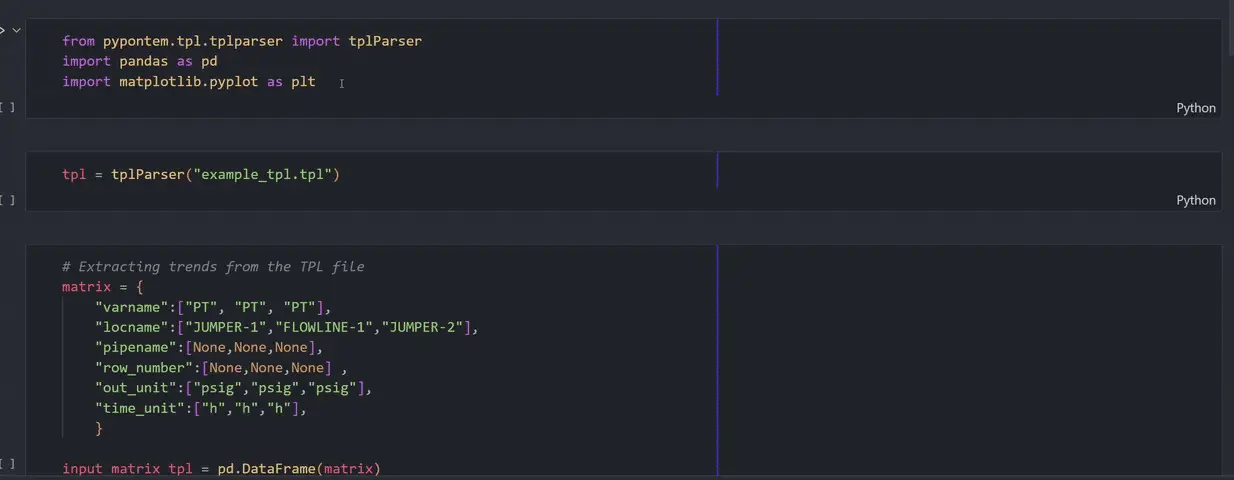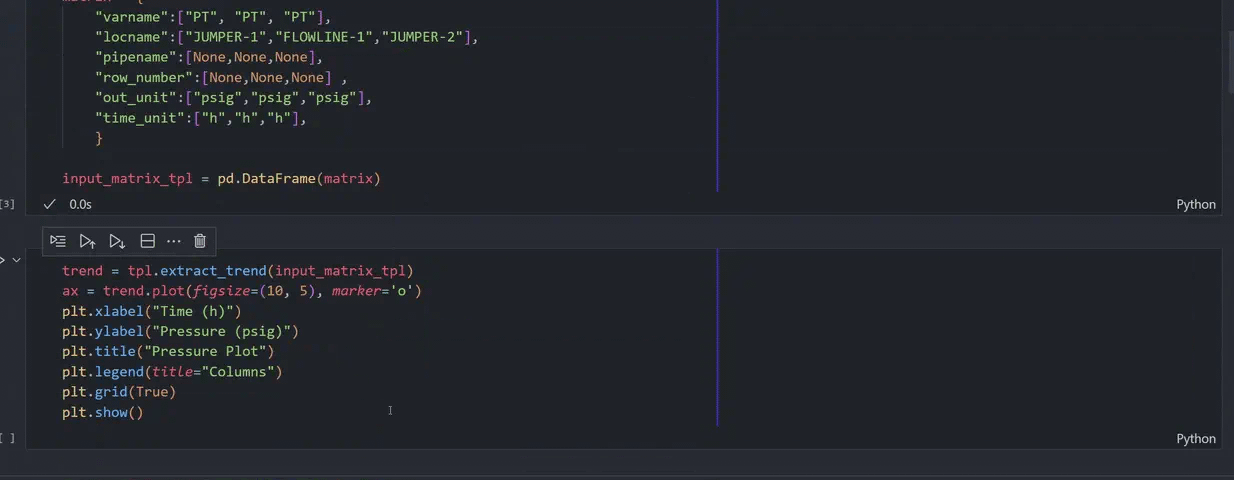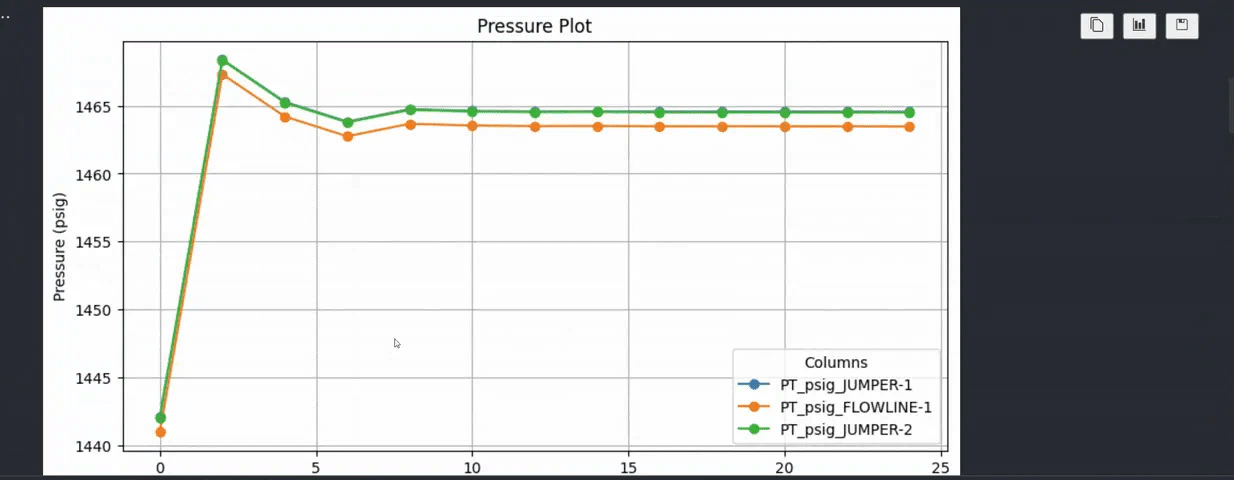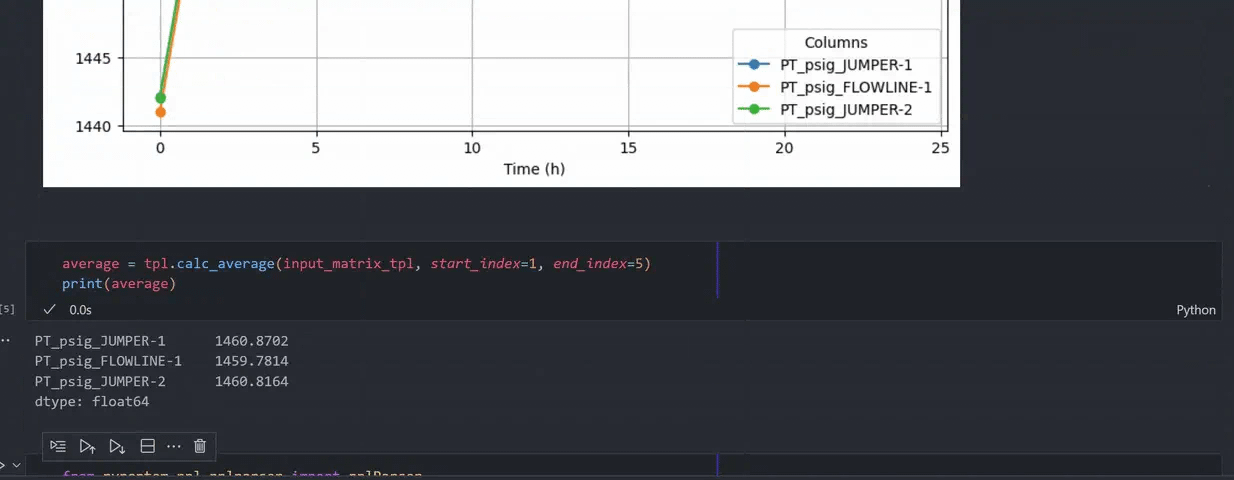
Harness data for analytics: You can run pypontem within a Jupyter notebook and seamlessly use the extracted data for plotting, statistical analysis or developing your own ML models
And so much more: Variable catalog search, branch profile and metadata extraction, it’s all there!
If there is a feature you would like which isn’t currently available, you can request it!
How do I get it and when can I start using it?
pypontem is available right now for install as a pip package! We also have a docs page, a Github repository and a Github Issues page.

Stay tuned
pypontem is a big step for us in bridging data and discipline while contributing to open source and helping to push the industry forward.
This article was meant to be an introduction. Later this week, we will be following it up with a more detailed walk through of key functionality in pypontem, so stay tuned!