
Future of Knowledge Management in Oil and Gas
Databricks, LLMs, RAG and more...


Earlier this week, we announced our partnership with Databricks . Now, we’d like to dive deeper into the technical details and capabilities of Databricks, along with insights on one of the ways we intend to leverage it.

Databricks has emerged as a leading platform for data engineering, machine learning, and artificial intelligence. While many in our industry may have heard of Databricks, it’s worth diving deeper into what the platform actually does and why it has become such a game-changer in the world of data-driven solutions. After all, we at Pontem are now partnered with what is considered a unicorn in the investment world, currently valued at over $62 billion in their latest fundraising round...
From Data Chaos to Clarity: Powering Real-Time Insights
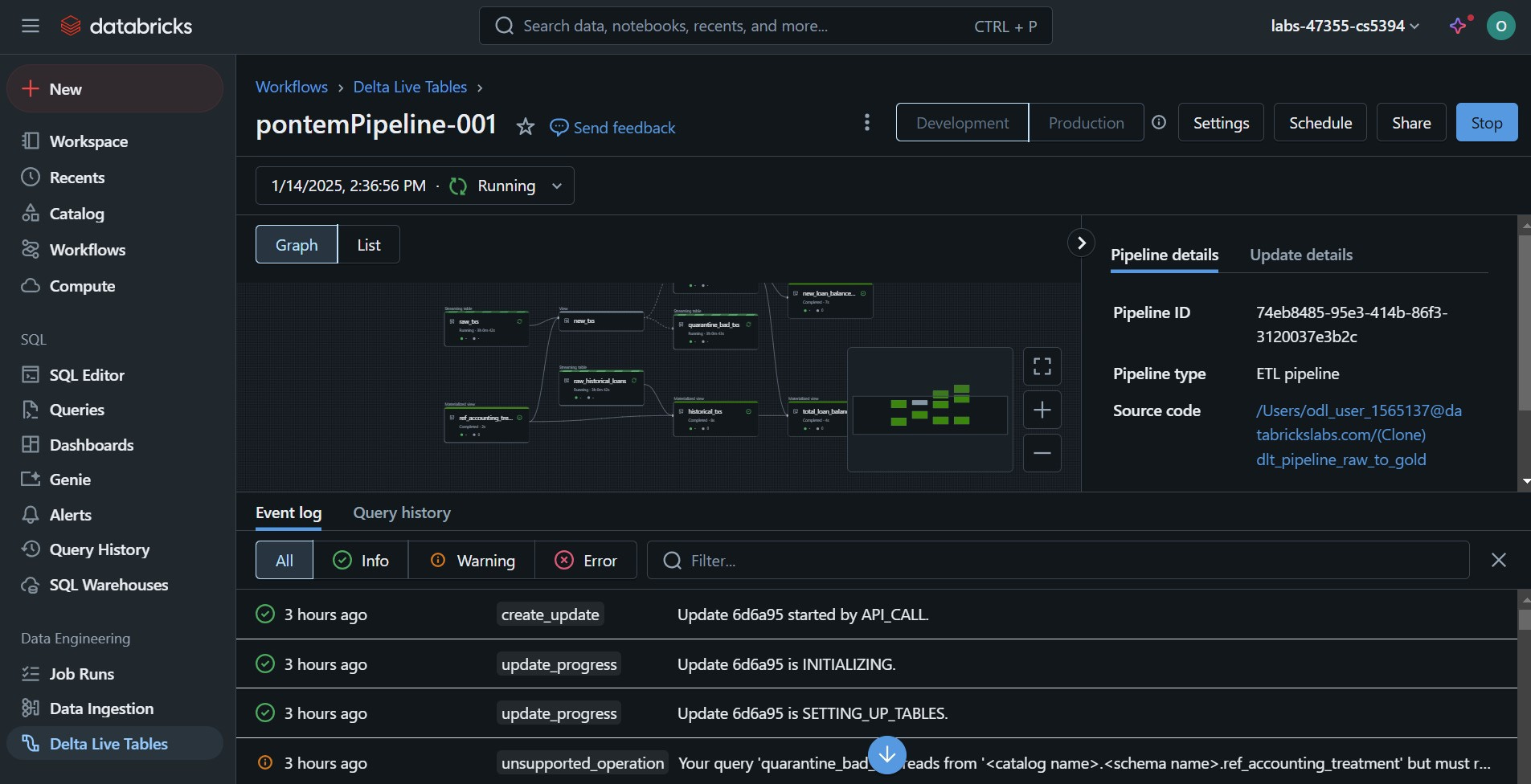
Imagine a company trying to build a real-time dashboard to monitor operations, track performance, or detect anomalies. While the idea sounds simple, teams often struggle when they start such a project because they quickly realize the data they need is scattered across different systems, it arrives in different formats, and it requires cleaning before it’s usable.
A reliable data pipeline solves this by doing three essential things:
Collecting Data: It pulls information from multiple sources, such as sensors, control systems, or production databases, bringing all the data together in one place.
Cleaning and Organizing: It removes bad readings, standardizes data formats, and ensures all information is complete and accurate, making it reliable for analysis.
Delivering Processed Data: It sends clean, real-time data to the dashboard, ensuring that decision-makers have up-to-the-minute insights to monitor performance, identify anomalies, and optimize operations.
As a company that also specializes in production assurance for oil / gas pipelines, you can think of these data pipelines as facing a similar metaphor of “flow” obstacles.
This is where Databricks comes in. It provides a unified platform that streamlines the ability to setup these data pipelines. Everything you need from the data storage to the data cleaning scripts, all the way to the advanced machine learning models producing the results for the dashboard are all contained in one tool.
At Pontem, we use the Databricks platform to easily setup the needed infrastructure to enable rapid and successful deployment of digital solutions.
Commercial Use of LLMs: Unlocking AI-Powered Intelligence
Another key area where Databricks provides significant value, and something we’ll focus on for the rest of this article, is in the commercial application of Large Language Models (LLMs). By this time, most people have probably interacted with the likes of ChatGPT and so you are probably familiar with LLM’s, whether you know them by that name or not.
These AI-driven models, trained on vast datasets, have revolutionized how businesses interact with and process information. LLMs can summarize documents, answer complex questions, and even generate entirely new content, making them a game-changer for industries looking to automate and enhance decision-making (or for your typical high-schooler looking for help on their English essay).
Underneath the class of LLM’s, is another rapidly emerging idea called Agents, which take the idea of LLM’s one step further. Unlike traditional LLMs that simply respond to queries, Agents operate interactively within a specific environment. They can retrieve real-time data, execute workflows, and provide context-aware insights—essentially blending the reasoning capabilities of AI with the retrieval efficiency of a search engine and the domain knowledge of an expert.
This idea is gaining momentum, especially as Databricks integrates LLMs with real-time data pipelines, enabling businesses to develop AI systems that are not only intelligent but also continuously update with the latest organizational data. By leveraging Databricks’ unified platform, companies can build AI-driven solutions that are more informed, efficient, and tailored to their specific needs.
LLMs are great, but LLM’s with a data pipeline behind them to constantly update with supplemental information are even better.
Diving Deeper: Retrieval-Augmented Generation (RAG)
One of the key advancements in LLMs, and a crucial piece of enabling Agents, is the development of Retrieval-Augmented Generation (RAG). RAG enhances traditional LLMs by pairing them with real-time retrieval systems. Instead of relying solely on pre-trained data, RAG-enabled models can query live databases, repositories, or reports to generate accurate, up-to-date, and context-specific responses.
Here’s how RAG works:
Retrieve: When a query is made, the system first retrieves relevant information from structured or unstructured data sources, such as technical reports, field logs, or design documents.
Generate: The LLM then synthesizes this retrieved information into a coherent and actionable response, providing context and accuracy far beyond what traditional AI models can achieve.
In the industries that Pontem serves, success depends on leveraging years of accumulated technical knowledge. In these instances, RAG is a game-changer. It allows AI systems to combine the vast knowledge embedded in documentation with real-time situational data, offering insights that are both comprehensive and precise.
LLM’s that can update with supplemental information are great, but LLM’s that can update with relevant information specific to your company are even better.
Why Meta’s Llama Stands Out Compared to OpenAI
When discussing LLMs, OpenAI’s GPT models and ChatGPT often take center stage (although just this week, you may have likely heard of the up-and-comer DeepSeek also jumping into the scene). However, Meta’s Llama models have emerged as a strong alternative, especially for enterprise and industrial applications. Here’s why:
Open-Source Flexibility: Unlike OpenAI’s models, Llama is open-source, allowing organizations to customize and fine-tune it for their specific needs. This level of adaptability is crucial for industries like oil and gas, where domain-specific knowledge and terminology play a critical role.
Data Security and Privacy: With Llama, models can be deployed in secure, private environments. For businesses handling proprietary or sensitive data, this is a significant advantage over API-based models that rely on external servers.
Cost Efficiency: The ability to run and fine-tune Llama models locally or on platforms like Databricks often translates to substantial cost savings, especially for large-scale deployments.
Why Databricks Is Uniquely Positioned
What makes Databricks the perfect platform for integrating Llama? Its unified data and AI framework. Databricks offers tools for pre-processing, managing, and analyzing the massive datasets that feed LLMs while also providing seamless infrastructure to train, deploy, and scale models. This ecosystem allows businesses to fully leverage the power of LLMs like Llama without compromising on security or performance.
LLM’s that can update with relevant information specific to your company are great, but adding in open source flexibility and high-level data security is even better
What’s Next?
At this point, we have discussed the idea of data pipelines and why they are critical to any successful data-driven solution. As we explore these capabilities including Databricks, LLMs, and emerging technologies like RAG, we’re working on exciting projects that can redefine how technical knowledge is accessed and used in the oil and gas industry. We believe that as a company, Pontem’s ability to offer deep domain knowledge while simultaneously being able to navigate state of the art technology, makes us uniquely qualified to create and deploy revolutionary workflows that enhance decision-making and unlock new levels of efficiency.

Lot more to come on this so stay tuned for updates as we continue to innovate in this space….
Interesting read. Would love to learn more about this collaboration.