
Doing it right: The case for MLOps
Move beyond just Jupyter Notebooks, MLOps now!

Imagine this scenario:
You’re a recent data scientist hire in a burgeoning company. Your first task is to support a project where various machine learning models were deployed a few quarters ago. The folks who did the development are no longer with the company. The client is now complaining that the deployed model predictions have degraded drastically in performance as these models were making business critical predictions.
How would you begin to address this?
No matter how you approach this problem, you have to agree that some sort of documentation/traceability is a necessity to even begin diagnosing the issue. This is where MLOps comes in!
What is MLOps?
MLOps or Machine Learning Operations, derived from software DevOps, is the term used to describe a broad set of operations ensuring traceability and maintainability for various processes within the ML development lifecycle. The figure below is an overview of some of these processes. These include everything from exploratory data analysis to development and deployment of models to monitoring performance and triggering re-training where applicable.

These steps are:
EDA: Exploratory data analysis to determine trends, patterns, data types, how much data is missing, what are the important features for what you want to model/predict
Data Prep: Cleaning the data by denoising, filling in missing values and dropping non-relevant features
Develop: Develop and train your feature engineering and prediction pipelines
Review: Review performance of model pipeline with key stakeholders
Deploy: Deploy model into production environment
Inference: Make predictions on incoming data in the production environment
Monitor: Monitor the performance of the model in terms of accuracy, prediction error in terms of regression tasks or precision, recall etc. for classification tasks
Retrain: If model performance degrades over time with new data, it is time to retrain the model
Machine learning projects involve 2 main components, code and data. While DevOps lays out the best practices for deploying and maintaining code (think APIs and version control) handling data is a relatively newer, challenging problem. MLOps borrows a lot of the same principles but the additional dynamic component of handling data, especially in production environments, as opposed to just static software, makes it a harder challenge.
When deploying models that interact with real world data, it is crucial to anticipate that the data is always prone to changing and thus the models deployed have to adapt to these underlying changes. While this is easily understood in retail spaces due to changes in real world trends, this also affects engineering and physical models. For e.g. if your machine learning model predicts subcooling and hydrate formation but water production has increased beyond what was expected.
What are some MLOps best practices?
The following are some of the basic MLOps practices to adopt at various stages of a project:
EDA
Data versioning (tracking different versions of raw and processed data)
Versioning Jupyter notebooks and Python scripts
Creating shareable visualizations which appropriately named and saved
Data prep
Tracking feature engineering steps
Model development
Code versioning
Tracking training and test datasets and developed prediction pipeline artifacts
Logging experiments and hyper-parameters
Model deployment and monitoring
Pre-deployment tests to identify failure conditions for the prediction pipeline
Data integrity and stability tests to monitor data drift in production environment
Logging inference data, predictions and metrics
Definition of retraining triggers
When should you use MLOps and who are the stakeholders?
Obviously, setting up MLOps pipelines and procedures take a little more work than simply writing and running a program in a Jupyter notebook. So when should you invest time in MLOps procedures? Conventionally, there are thought to be 3 levels of MLOps implementations:
Level 1: Essentially at level 1 there is little to no MLOps. Most machine learning projects live in level 1, wherein you are experimenting or developing a proof-of-concept which resides mostly in stand-alone Jupyter notebooks or Python scripts. Usually, the developed models are not deployed in a production environment. Due to a lack of MLOps procedures, there is limited reproducibility and data and models are not tracked
Level 2: At this level, instead of models you are developing pipelines, you’ve moved out of developing models within Jupyter notebooks, the aim is to deploy in a production environment with continuous monitoring and retraining when necessary. The pipelines are reproducible and reusable and all code, artifacts and experiments are tracked. This level is typically used for small/medium teams with moderate infrastructure needs.
Level 3: This level is essentially continuous integration and continuous deployment (CI/CD) of the different deployed pipeline components. At this level, there is more automation and a change in any component will trigger tests and automatic deployment once the tests are passed, into the production pipeline. This includes continuous training of models as soon as new data arrives. This level is typical of very large organizations with large teams and significant infrastructure.
Some of the key stakeholders during the MLOps process are:
Subject matter experts: Involved from problem definition to post-deployment. SMEs often justify the business needs for ML model development, support data scientists during model development and provide feedback on model performance and compliance with regulations. It is therefore very important that there is transparency is built in the MLOps process, so that SMEs can understand why models perform the way they do.
Data scientists: Involved in developing model pipelines, test model performance, deploy into a production environment and monitor performance. Data scientists are mainly responsible for building reproducible, transparent workflows and automating packaging, delivery and retraining pipelines
Data engineers: Involved in setting up the data retrieval pipelines during deployment, setup monitoring dashboards and address issues with the data retrieval process
Software engineers: Responsible for front-end and back-end of the deployed model in the production environment and monitors software performance of the deployed solution
DevOps engineers: Responsible for building the operational systems within which the MLOps pipelines will be developed and the integration of MLOps into larger DevOps of the organization
Customers: The end-user of the model who will not see any of the underlying reproducible workflows, but will provide the final feedback of whether the model or product itself is satisfactory.
Depending on the size of your organization, you might be handling many of the above roles yourself, which makes it even more important that your workflows are reproducible and transparent.
What are some MLOps solutions/technologies?
Since the foundations of most ML projects are based on open-source technologies, there a lot of solutions and products which are available to handle different components on an MLOps operation. The figure below is an example schematic highlighting various technologies used for MLOps in various industries.
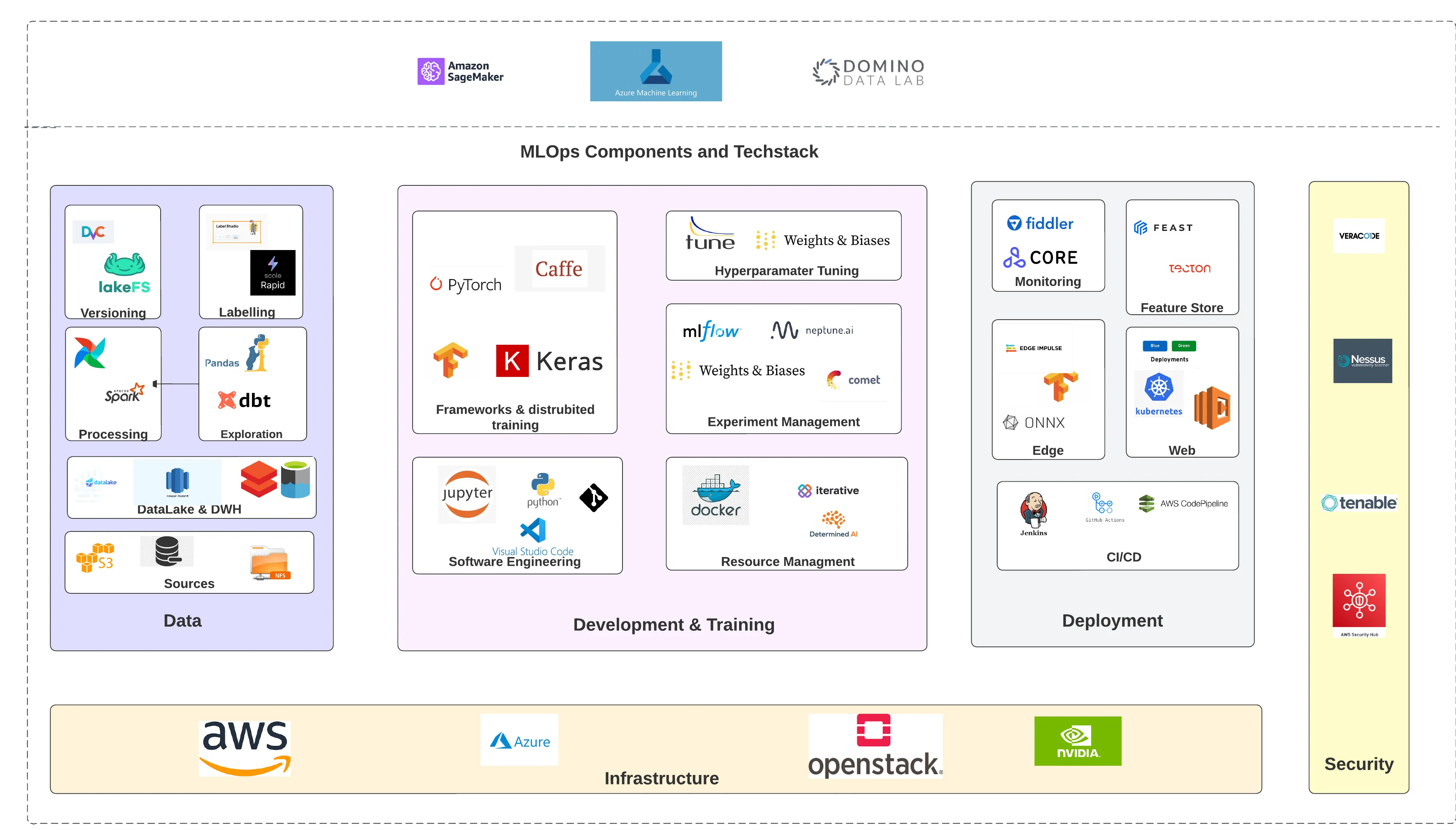
In addition, certain cloud platforms like Databricks and AzureML handle a lot of MLOps procedures using some of the solutions described above, so you don’t have to build everything from scratch.
Wrapping Up
Not all projects need comprehensive MLOps, however, most projects which are aimed at deployment will benefit from a degree of MLOps.
The next time you have to deploy a model to production, be sure to include as much MLOps steps as is feasible or necessary. It may take a little longer, but the value will be evident during post deployment diagnostics.
At Pontem, we are building our MLOps stack with many of the solutions described above, so stay tuned for exciting updates from some of the projects we are working on, with effective MLOps!